Are official statistics machine-understandable enough?
Analyzing ODIN to understand data readiness for AI
By Lorenz Noe
25 April 2024
The PARIS21 Spring Meetings in Washington, DC from 3-4 April brought together leading thinkers from national statistical offices (NSOs), international organizations, nongovernmental organizations, and the private sector to discuss the opportunities and risks that artificial intelligence (AI) presents for international development data. One central theme was the importance of good quality data to inform training data for AI algorithms, whether they train generative AI tools like ChatGPT or are used for other applications of AI. Open data from official statistics are a crucial component for evidence-based decision-making by humans and open data elements like metadata are important for ensuring data are human-understandable. In the age of advanced AI tools, it is similarly important to consider whether machine-understandable data hosted on the internet are well-documented when they are scraped and fed into training data for AI algorithms and then presented to human users of these tools. Although they do not make official statistics findable on their own, machine-readability and metadata availability are essential elements that determine whether data can be used by AI applications and whether AI can be used to improve data use and re-use. This blog digs into these two features to introduce what we know about the readiness of official statistics to take advantage of AI.
In Open Data Watch’s (ODW) Open Data Inventory (ODIN), which enters its seventh round in summer 2024, machine-readability and metadata availability are two of the five dimensions that define a country’s openness score. Scores for all openness elements have increased since 2016 (Figure 1). Terms of use are the worst performing category due to the lack of open data licenses, while the availability of data in non-proprietary formats (data that can be accessed without needing a paid-for-program) is the best performing element. Scores for machine readability and the availability of metadata fall in between. (For more information on these trends, see ODIN 2022/2023 Report.)
Figure 1 ODIN openness elements 2016-2022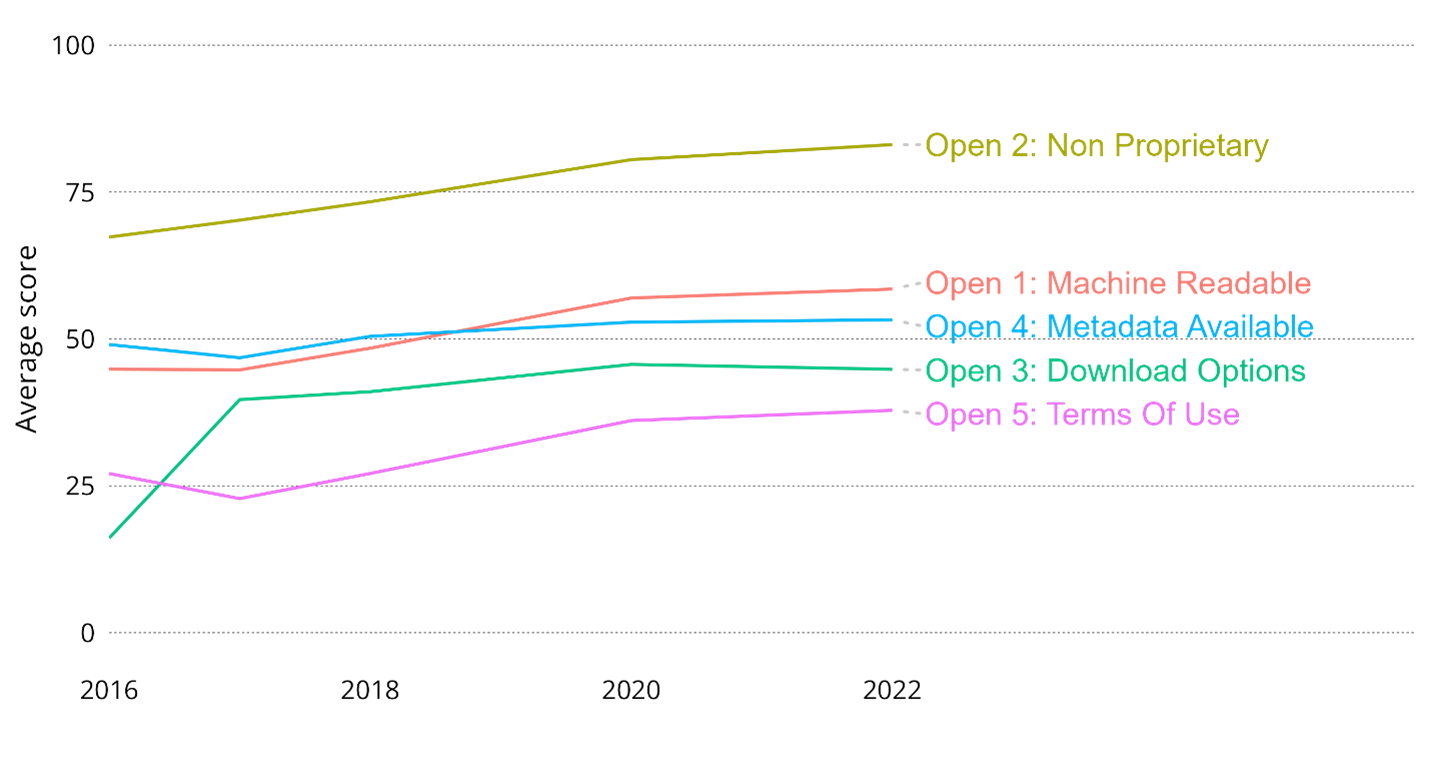
The machine-readability element score reflects the fact that of the 11 thousand unique records examined by ODIN 2022/23, slightly less than two-thirds (62 percent) come in machine-readable formats. The most popular machine-readable formats are XLSX and CSV, which are available for 71 percent and 48 percent of machine-readable records, respectively. Just under half of all machine-readable records have only one machine-readable format and a further 20 percent have two machine-readable formats. At the upper end, 5 percent of machine-readable records have six machine-readable formats. Many scrapers and everyday users can open and process XLSX and CSV files but the fact that so many machine-readable records only have one format available means that the work of standardizing data for analysis by AI may be more difficult.
Metadata in ODIN is defined by three components: Source, Date, Definition. These are a subset of the metadata specified by the schemas used by countries to report metadata (such as Metadata Structure Definitions that countries set up as part of SDMX), but they represent common descriptive and administrative components of metadata. The source of a dataset corresponds to the name of the responsible agency for the dataset, which helps users to know whom to contact for questions or what agency to cite. The date of the data refers to the specific date (day, month, and year) the dataset was uploaded to a website or when a dataset was last updated. Finally, the definition of the dataset refers to the definition of the indicator or a definition of key terms used in the indicator description (as applicable) or how the indicator was calculated. The combination of these three components allows a user to know who calculated a datapoint, how old the datapoint is, and how a datapoint was calculated. With this information the user can assess the quality and timeliness of a datapoint and whether this datapoint is relevant for their analysis. Machines that collect data via trawling the internet for data or local AI applications similarly can process information from the metadata to allow their algorithms to accurately reflect data that may be queried in a chatbot, for example.
Of the 11 thousand unique records that constitute the ODIN 2022 assessment, just over 90 percent have information on the source of the dataset and just over half have information on the date or the definition. This means that a user or a crawler might easily find information on the name of the source of the datapoint but would not know how to evaluate the suitability of the dataset due to a lack of description or assess whether the datapoint is recent enough for their use. Just over 30 percent of records have all three components of metadata, showing that official statistics are far from human or machine-understandable since this is a low bar to clear for metadata. Standards like SDMX are used by most major international organizations to document and exchange data and metadata. NSOs often use SDMX to ensure their data and metadata can be reported to regional and global custodian agencies. It is not possible to judge the adherence of NSOs to these standards in their internal data curation systems, but from ODIN’s user perspective, more data sources could be made machine-readable, and they could be better described by richer metadata. Further study of the various metadata schema employed by NSOs is needed to see where the weaknesses exposed by this topline analysis stem from.
Whether NSOs want to increase the usefulness of their data when they are collected by a data crawler or they want to use their own data to train algorithms that would lead to greater insights or to train chatbots as a tool for public consumption of their data, the records assessed by ODIN suggest that their data are often not available in machine-readable formats at all or not in enough formats. In addition, if data are available, they are often not accompanied by sufficient metadata. Both findings present significant technical hurdles to efforts by machine or human users to use the wealth of official statistics to derive better insights for better policy.
To employ the power of AI to improve the access and use of data and statistics, NSOs need to increase their focus and investments in tools, skills, and data management and stewardship for building better metadata and open data practices. At ODW, we will be extending our ODIN research and technical assistance work to support NSOs in their open data work to take advantage of the power of AI.





